








With 2.5 quintillion bytes of data created every day, it’s no wonder big data engineer jobs are skyrocketing. You are the architects, the wranglers, and the masterminds behind today’s constant flow of information.
The best big data engineer resume highlights your Hadoop skills and NIL-error accuracy. It proves your ability to deliver optimal user experience with today’s technology.
Above all, your resume demonstrates on-the-job success.
Stand out from the crowd by proving that you build data projects from ideation to launch. Let’s explore the top big-data resume examples that will help land you that interview.
This big data resume guide will teach you:
- How to demonstrate proficiency with a wide range of technologies and platforms within the limited space of a resume;
- How to translate your technical achievements into business outcomes;
- How to integrate soft skills and collaborative projects in a tech-dominated resume.
- How to tailor your resume to a job description so that it passes ATS filters and reaches human eyes.
Looking for something more specific? Here are some more data-related resumes.
- Data Analyst Resume Example
- Data Analyst Entry-Level Resume Example
- Data Engineer Resume Example
- SQL Developer Resume Example
- Test Engineer Resume Example
- Lead Data Engineer Resume Example
- Senior Data Engineer Resume Example
- AWS Data Engineer Resume Example
- Azure Data Engineer Resume Example
- GCP Data Engineer Resume Example
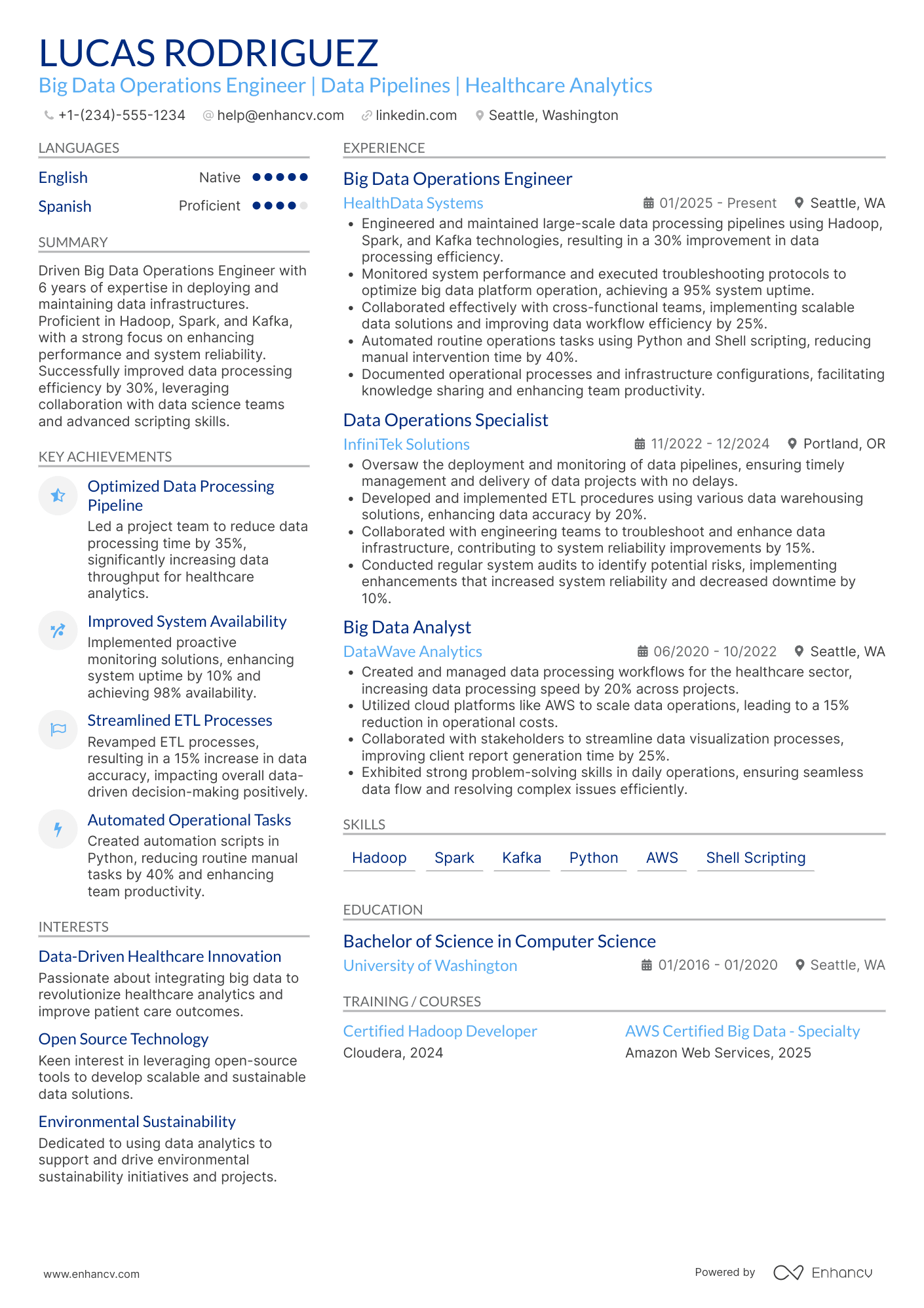
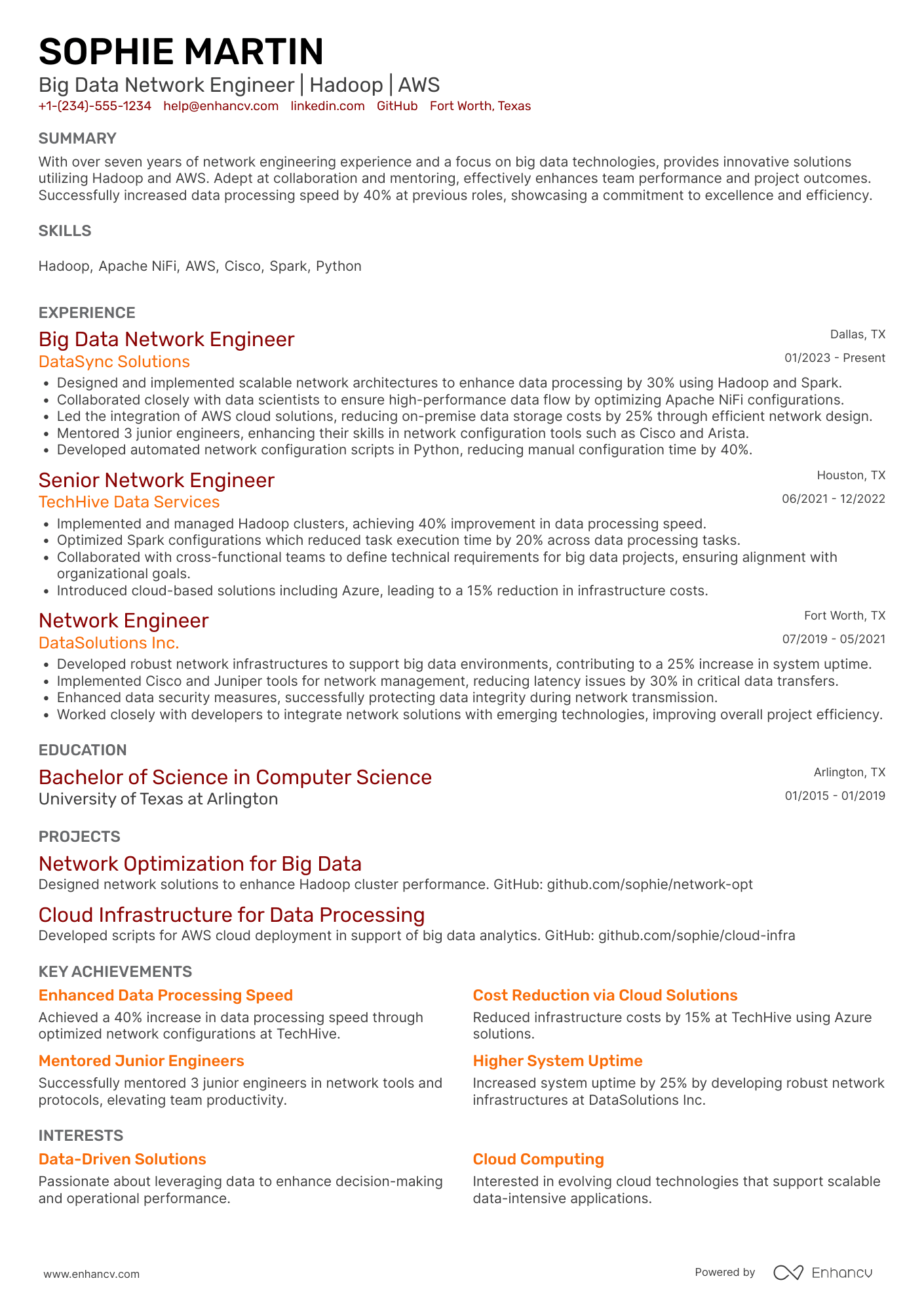
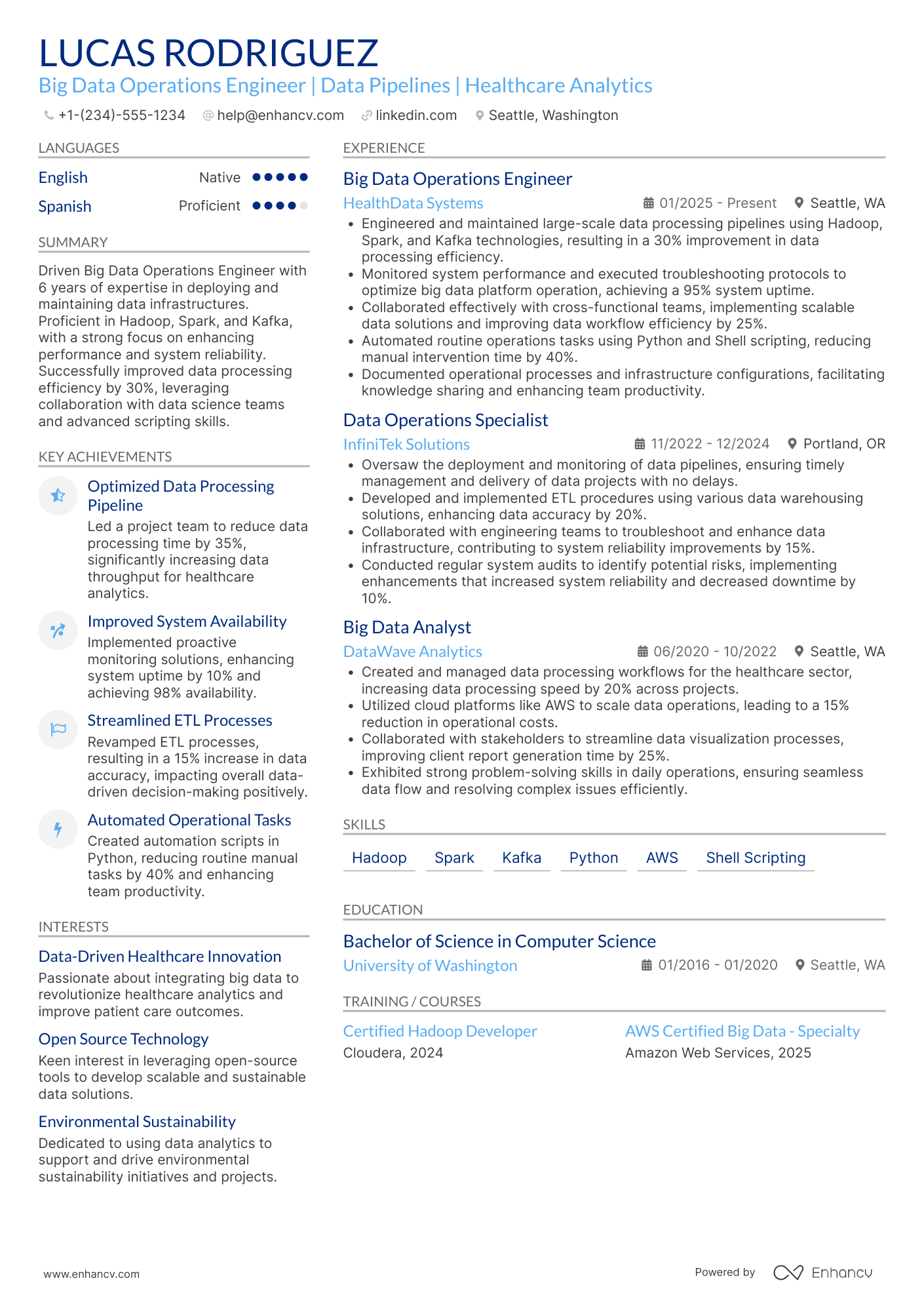
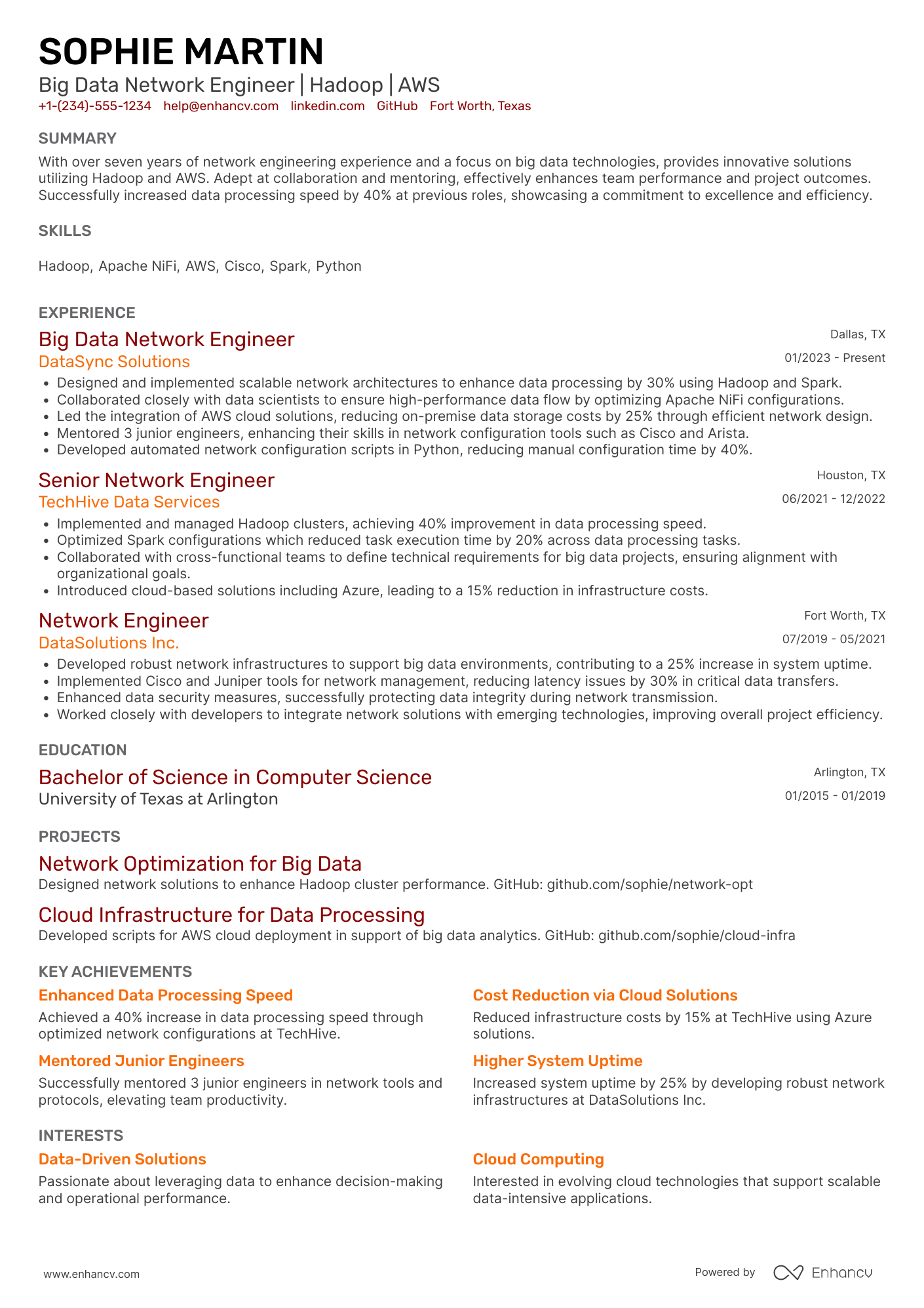
Big data engineer resume sample

Here’s what this applicant does well in their resume:
- Demonstrates significant achievements in big data engineering, such as leading projects that improved efficiency and reduced costs, which directly aligns with the demands of high-level engineering roles.
- Includes specific technologies and skills (e.g., Hadoop, Spark, AWS, Python) that are essential for the role, showcasing expertise and capability in relevant areas.
- Lists impactful projects and roles at prestigious companies (Google, Amazon, IBM), highlighting a track record of success in data engineering and analysis.
- Features advanced education and specialized certifications, reinforcing applicants' qualifications and commitment to their field.
How to format a big data engineer resume
big data engineers have a bird’s-eye view of the IT world. They don’t simply understand the long list of frameworks, tools, and DBMS programs. They use each of these tools to hone data streams and solve a specific problem.
The question is how to group everything you know into succinct informative sections.
A neat resume layout will make things way easier. Usually, big data engineers opt for a reverse chronological resume format, which provides a concise and detailed view of their employment history, starting with their most recent job first and going backward.
Additionally, big data engineers might consider the functional resume format, which emphasizes skills and experiences over chronological work history. This format is particularly useful for those who have gaps in their employment or are transitioning into big data engineering from a different field.
Another option is the combination (or hybrid) resume format, which merges elements of the two formats explained above. Such resumes begin with a strong skills section followed by a detailed work history in reverse chronological order. The combination resume allows big data engineers to emphasize their technical skills and accomplishments while also providing a clear timeline of their professional experience, making it a versatile choice for those with a solid career trajectory and specialized expertise.
Resume designs
- Create a clear resume header with your name, job title, and location. You can also use a distinctive color for it to make it more eye-catching.
- Include a link to your LinkedIn profile or GitHub repository showcasing your contributions to open-source projects and coding skills. This is particularly useful for demonstrating your expertise and dedication to the field.
- Omit a resume photo to maintain focus on your qualifications and avoid potential biases.
- Use a traditional or minimalistic template to keep things organized and professional.
- Go with sans-serif fonts sized 10 to 12 pt. to ensure accessibility. Maintain resume margins between 0.5 and 1 inch to keep the document neat and readable.
- Save your resume as a PDF file so the formatting remains consistent across different devices.
Tailor your resume format to the job market – a Canadian resume, for example, might differ in layout.
If you already have a resume, run it through an AI-powered resume checker to see how it scores against a real ATS.
Is your resume good enough?
Drop your resume here or choose a file. PDF & DOCX only. Max 2MB file size.
This is just the beginning. According to our research, these should be the most prominent sections on your resume:

The top sections on a big data engineer resume
- Technical skills and certifications to demonstrate expertise in big data tools and technologies.
- Relevant big data projects showcasing practical experience and impact on business outcomes.
- Professional experience in big data to highlight roles and contributions in the field.
- Education and continuous learning indicating foundational knowledge and commitment to staying updated.
- Data analysis and visualization tools to show proficiency in extracting insights from big data.
Then, remember: hiring managers look at hundreds of resumes. Unlike data scientists and data analysts, you need to show you can construct systems that transform how a company views its data’s potential.
If you’re right for the position, you should be able to include (and prove) each of the skills, software names, and experiences from the job post.
What recruiters want to see on your resume
- Proficiency in big data technologies (e.g., Hadoop, Spark, Kafka) because they are crucial for managing and processing large datasets.
- Experience with data modeling and database design, as it demonstrates the ability to structure and optimize data for efficient querying and analysis.
- Ability to implement data pipelines and ETL processes, highlighting skills in data extraction, transformation, and loading which are essential for data preparation and integration.
- Familiarity with cloud services (e.g., AWS, Azure, Google Cloud) because cloud platforms are commonly used for scalable big data storage and processing.
- Strong analytical and problem-solving skills, showing the capability to derive insights and solutions from complex datasets.
Quite a lot for a 1- or 2-pager, right? Worry not. We’ll tackle each requirement in the guide below.
How to write a big data engineer resume experience
You’re a big data engineer and your experience is… well, big. You need to be strategic about what to add and what to remove from your resume to make sure you communicate the most significant aspects of your work history, backed by tangible results.
Here’s how you should approach crafting your experience section:
- Highlight relevant software, tools, and frameworks you've used, especially those mentioned in the job posting, to demonstrate your technical proficiency.
- Include soft skills and unique experiences that distinguish you from others in the field, such as problem-solving and project management within specific industries (e.g. healthcare or entertainment).
- Detail specific instances where you utilized your skills to solve complex data problems, showcasing your ability to apply training and certifications to achieve tangible results.
- Use quantitative data whenever possible to prove your successes.

PRO TIP
These guidelines help you create a targeted resume. This simply means that you tailor the content to specific keywords from the job description, making sure that the skills and qualifications that you match are prominently displayed on your resume. This approach leads to better ATS scores and better chances of getting an interview call.
Let’s look at an example of an experience section done wrong.
 02/2021 - 11/2023
02/2021 - 11/2023 
- •Mentored a team of junior data engineers.
- •Used Java and Scala.
- •Maintained current ETL workflow.
- •Designed data processing pipelines.
The information here is too generic. We can’t figure out the where, how, or why in these bullet points. Above all, there’s no story on the page. Let’s turn that around:
02/2021 - 11/2023 - •Lead a team of 15 junior data engineers at nationwide entertainment company.
- •Utilized Java and Scala to maintain and optimize existing ETL workflows, enhancing data integrity and processing speed.
- •Designed and implemented innovative data processing pipelines, resulting in a 30% improvement in data handling efficiency.
- •Conducted comprehensive training sessions on Python, SPARK, and Parquet formats for colleagues, enhancing the team's programming skills and data processing capabilities, leading to a 25% increase in project delivery speed and efficiency.
So much more impactful! Here’s why:
- Clear metrics: the applicant uses specific metrics to demonstrate impact, making achievements tangible and credible.
- Leadership and tech skills demonstration: those are implied, instead of explicitly mentioned. Employers appreciate multifaceted candidates.
- Industry-specific skills: highlighted proficiency in key big data technologies, aligning closely with job requirements in the field.
Want to achieve the same on your own resume? Read on to learn how to measure impact in big data engineering.
How to quantify impact on your resume
Including quantified impact in your resume helps communicate your accomplishments more effectively and showcase your contributions in a way that is clear, measurable, and impressive.
You can maximize your resume potential with the following tips:
- Include the volume of data you've managed or processed. Big data engineers should be able to demonstrate their ability to handle large-scale data infrastructures.
- Mention the percentage increase in data processing speed after optimizing ETL workflows. This shows efficiency improvements.
- Detail the reduction in data storage costs achieved through effective data management strategies. Stand out as someone with a cost-saving mindset.
- Quantify the improvement in data accuracy or quality as a result of your data validation processes.
- Describe the increase in analytics speed or efficiency due to your pipeline enhancements to underscore your impact on decision-making processes.
- Specify the growth in user engagement or customer satisfaction metrics due to your data-driven product improvements.
- Report the decrease in system downtime from your maintenance and optimization efforts, showcasing reliability and operational efficiency.
- Highlight the revenue growth or cost reduction achieved through your big data initiatives, linking your work directly to business outcomes.
That’s great, but what if you’re trying to land your first job in big data engineering?
You can still get noticed, just follow our tips below.
How to write a big data engineer resume with no experience
An entry-level big data engineer will typically do simple data analysis, learn how to implement technologies and, of course, do a lot of troubleshooting.
But before you get to that, you need a resume that gets you the job.
A junior big data engineer should focus on several key elements to stand out and demonstrate their potential value to employers:
- Educational background. Highlight your degree(s) in Computer Science, Data Science, Information Technology, or related fields. Talk about any related classes or projects you've done that involve big data, databases, or analyzing data.
- Resume objective: This type of professional profile is no more than 3 sentences long and focuses on your career aspirations rather than your work history. This makes it especially suitable for entry-level candidates.
- Technical skills. List your technical skills, including programming languages (e.g., Python, Java, Scala), big data technologies (e.g., Hadoop, Spark, Kafka), and database management systems (e.g., MongoDB, Cassandra), and any other relevant software or tools (e.g., Git, Docker) that you’ve learned.
- Internships and projects. Detail any internships or academic projects that involved big data technologies or concepts. Describe your role, the technologies used, and the outcome or insights gained from the project. Quantify your achievements.
- Certifications and courses. Include any additional certifications or online courses you've completed that are relevant to big data engineering, such as courses on Udemy, Coursera, or certifications from Cloudera or AWS.
- Participation in relevant extracurricular activities. If you've been involved in coding clubs, hackathons, or data science meetups, include these experiences. They demonstrate your passion for the field and your proactive approach to learning and applying big data technologies.
- Soft skills. Big data projects often require collaboration across different teams, so it's important to mention your soft skills. Highlight your ability to work in a team, communicate effectively, and solve problems creatively.
Now that we’ve mentioned skills, we need to pay special attention to this resume section, as a strong combo of hard and soft skills is greatly appreciated.
How to list big data skills on your resume
Big data developers speak a unique language. They must be able to access a mass of information from a growing list of today’s technologies.
When listing your hard skills, Include all the programs, languages, and frameworks specified in the job posting. Also, include all programs mentioned in your work experience section.
Best hard skills for a big data engineer resume
- Hadoop
- Spark
- Kafka
- Python
- Scala
- Java
- SQL
- NoSQL databases (e.g., MongoDB, Cassandra)
- ETL tools
- Hive
- HBase
- MapReduce
- Cloud platforms (AWS, Azure, Google Cloud)
- Docker
- Kubernetes
- Machine Learning algorithms
- Data visualization tools (e.g., Tableau, Power BI)
- Apache Flink
- Elasticsearch
- BigQuery
Soft skills are just as crucial for data engineers. Your role requires constant collaboration to solve complex issues and communicate solutions with your peers. However, unlike technical skills, your people skills shouldn’t be merely listed in a separate section. Instead, integrate them into various sections of your resume, such as the experience or summary sections. Then, you should provide specific examples that demonstrate your mastery of each skill.
For example, don’t just say you have great problem-solving skills. Mention it in your experience section entries like so: ‘Developed and implemented a data pipeline optimization strategy, reducing data processing time by 30% and improving system efficiency, resulting in a 20% decrease in operational costs’.
Check out the most popular personal skills to showcase throughout your resume.
Best soft skills for a big data engineer resume
- Analytical thinking
- Problem-solving
- Communication
- Teamwork
- Adaptability
- Time management
- Attention to detail
- Creativity
- Critical thinking
- Leadership
- Project management
- Initiative
- Persistence
- Negotiation
- Emotional intelligence
- Decision-making
- Stress tolerance
- Curiosity
- Empathy
- Conflict resolution
Having the essential skills covered, let's delve into the certifications that can further validate your expertise and technical proficiency in data engineering.
How to list certifications and education on your resume
Many big data engineers get their start with a base of certifications. Demonstrating your skills is the key, but it all begins with proper training.
So, list all relevant and job post-specific certificates on your big data engineer resume. You can get inspiration from us:
Best certifications on a big data engineer resume
Keep in mind that certifications have expiration dates for a reason, especially in the tech industry where innovations emerge daily. So, when listing your certifications, always include both the expiration date and the issuing organization to ensure your qualifications are current and validated.
Regarding your educational background, the education section is a big part of the story, even if you took an indirect path to a career in data engineering.
Education shows where you obtained your foundation of skills like SQL and Java training. It proves if you originally came to big data from a statistical, IT, or business background. Students often begin with data science analytics, computer science, or statistics degrees. Include specific coursework that hits those job posting keywords one more time. Did you receive invaluable training during a mentorship with a notable expert? Add this here as well!
Here’s a good example of a big data engineer’s education section:
02/2000 - 11/2004 - •Relevant coursework: Data Structures, Algorithms, Database Systems, Big Data Analytics, Machine Learning
- •Projects: Independently completed a portfolio-ready Guided Project on NoSQL Database with MongoDB and Compass
If that’s not enough to impress recruiters, nailing the resume summary will.
How to write a big data engineer resume summary
The big data resume summary showcases who you are as a professional. It encourages the reader to read further while reassuring them you took the time to read their job post.
This is the place to highlight relevant skills, certifications, and experiences specific to the job.
If the job posting suggests a must-have skill, be sure to include this in the professional statement upfront.
Let’s see two examples of a resume summary, starting with the bad one.
Smells like missed opportunities, right? Here’s why:
- The summary lacks specific examples of achievements or quantifiable results, making it difficult to gauge the candidate's impact in previous roles.
- It does not mention any soft skills or the ability to work within a team, which are crucial for collaborating on big data projects.
- The statement is too generic and does not differentiate the candidate from others in the field.
This section is your elevator pitch. Start with a strong introductory phrase stating who you are. If a pro asked what you do, how would you respond?
Use active verbs and data that back up your findings. Include the number of years of experience, specific industries you’ve served, and how you solved a company’s data problems.
Now, look at the improvements.
- This version showcases extensive experience and specialization in big data technologies, providing a strong background context.
- It highlights proven capability in handling large datasets and applying advanced statistical methods, which is valuable for potential employers.
- The mention of teamwork and collaboration with data specialists to create machine learning applications demonstrates interpersonal skills and the ability to work on innovative projects.
Lastly, apply only for positions where demonstrated experience aligns with the job requirements. Tailor your resume summary to each job description. Enhancv’s resume builder allows you to customize your resume to meet specific job requirements, making multiple changes as needed.
Optimize your resume summary and objective for ATS
Drop your resume here or choose a file.
PDF & DOCX only. Max 2MB file size.
How to feature projects on a big data engineer resume
Adding a section to discuss job-relevant projects allows you to showcase your technical expertise and problem-solving skills. These projects can be work-related, academic, or personal. A project section is particularly beneficial for people with less than 5 years of work experience.
So how do you effectively highlight data engineer projects on your resume?
- Focus on relevance. Choose data projects that match the job description and meet the company's needs closely.
- Showcase complexity. Select projects that address tough data challenges or demand creative solutions.
- Demonstrate a broad skill set. Present a variety of projects that highlight your diverse skills, from data cleaning to machine learning applications.
Key takeaways
As a big data engineer, making your resume pop is almost as challenging as explaining what you do at family dinners — here's how to nail it and showcase your journey.
- Include all required information from the job posting. Make sure your resume directly addresses the qualifications and skills the employer is seeking.
- Highlight demonstrated skills and problem-solving experience, using specific examples from your past work to show how you've tackled challenges and applied your skills in real-world situations.
- List experiences in reverse chronological order. Starting with your most recent job gives recruiters an immediate view of your current capabilities and how you've progressed over time.
- Pinpoint industry-specific and niche experience. If you've worked in areas particularly relevant to the job or industry, make sure these stand out.
- Showcase your drive and curiosity for pursuing this career. Let your passion for big data engineering shine through by mentioning any continuous learning efforts, side projects, or ways you stay updated with industry trends.
- Create a cohesive narrative and feature the keywords from the job post. This helps recruiters see the bigger picture of who you are as a professional and how you've arrived where you are today.
Big Data Engineer resume examples
By Experience







By Role